Mikrotik Bridges
TL;DR: Bridges sind einer der grundlegenden Bausteine einer Mikrotik Router-Konfiguration. Und nicht nur hier, im kompletten SDN-Umfeld sind Bridges nicht wegzudenken. Grund genug, um sie im Detail zu verstehen.
Wir werden uns also in diesem Artikel Mikrotik Bridges detailliert ansehen. Angefangen mit den Grundlagen, über die Interaktion zwischen den Bridges und den damit entstehenden Herausforderungen, wie man eine Bridge performant konfiguriert und Bottlenecks identifiziert und abschließend, wie Traffic in und aus einer Bridge fließt und wie man hier eingreifen kann. Der Fokus liegt dabei immer auf den Mikrotik Bridges, es ist aber an manchen Stellen für das Verständnis sinnvoll, etwas weiter auszuholen. Jeder, der mit den Netzwerk-Grundlagen vertraut ist, sollte mit dem Artikel zurechtkommen. Wird es zu spezifisch, verlinkte ich gerne auf externe Quellen.
Grundlagen
Die meisten Mikrotik-Geräte mit RouterOS haben einen oder mehrere Ports (oder auch Interfaces genannt), über die Netzwerk-Traffic ein und aus gehen kann. Meist sind diese Ports Ethernet-Interfaces mit unterschiedlichen Charakteristiken (Bandbreite, Übertragungsart, ...). Jeder Port repräsentiert sein eigenes LAN-Segment, auch Broadcast-Domain genannt.
Um nun eine Kommunikation zwischen den Ports herzustellen, gibt es das Konzept einer Bridge. Sie operiert im OSI-Modell auf Layer 2, sprich auf Basis von MAC-Adressen. Wie ein virtueller Switch werden so verschiedene LAN-Segmente zu einem zusammengefasst und stellen dann eine einzige Broadcast-Domain dar. Da die Bridge auf Layer 2 arbeitet, ist sie mit allem kompatibel, was eine MAC-Adresse hat (Ethernet, Wireless, Bonding, VLANs, ...). Was das genau bedeutet und welche Implikationen dies mit sich bringt, klären wir jetzt.
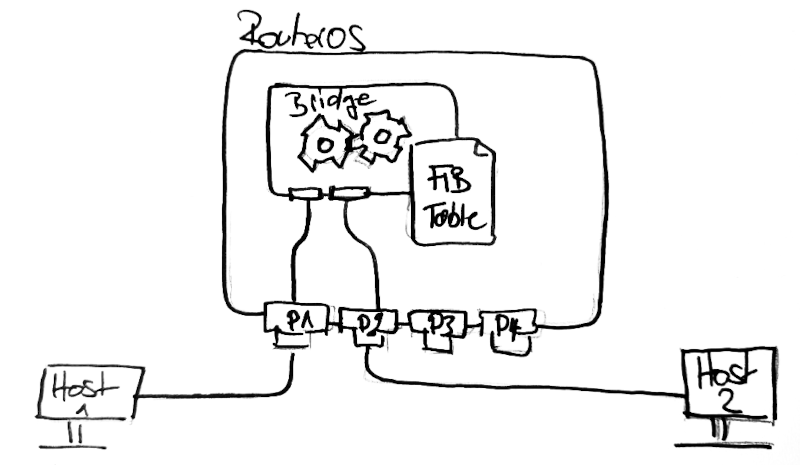
Erstellen wir nun eine einfache Bridge (mit dem Namen Bridge), die die Ports P1 und P2 in eine gemeinsame Broadcast-Domain setzt:
/interface bridge add name=Bridge
/interface bridge port
add bridge=Bridge interface=P1
add bridge=Bridge interface=P2
Wichtig hierbei ist, dass ein Port nur in einer Bridge gleichzeitig sein kann. Ist ein Port in einer Bridge, wird dieser als Slave (S) gekennzeichnet und ist somit nur noch durch die Bridge erreichbar.
Layer 2
Auf Schicht 2, dem Data Link Layer, gibt es keine IP-Adressen, keine Firewall-Regeln (auf IP-Basis) oder Anwendungsprotokolle. Hier geht es um die einzelnen Ethernet-Frames (Auch IP-Datagram oder MAC Layer PDU genannt) und wie diese den Weg durch die Netzwerk-Ports von der Quelle zum Ziel finden.
Jeder Port besitzt eine einzigartige MAC-Adresse. Diese ist fest in der Hardware kodiert und ist weltweit eindeutig. Im Beispiel oben haben die Ports 1-4 jeweils eine eigene MAC-Adresse. Aber auch die Ports der beiden Hosts haben jeweils eine, und da unsere virtuelle Bridge ebenfalls auf Layer 2 arbeitet, hat sie ebenfalls eine MAC-Adresse.
Dies können wir uns mit /interface print ansehen:
Flags: R - RUNNING; S - SLAVE
Columns: NAME, TYPE, ACTUAL-MTU, L2MTU, MAC-ADDRESS
# NAME TYPE ACTUAL-MTU L2MTU MAC-ADDRESS
0 RS P1 ether 1500 0C:74:A8:FC:00:01
1 RS P2 ether 1500 0C:74:A8:FC:00:02
2 P3 ether 1500 0C:74:A8:FC:00:03
3 P4 ether 1500 0C:74:A8:FC:00:04
8 R Bridge bridge 1500 65535 0C:74:A8:FC:00:01
9 R lo loopback 65536 00:00:00:00:00:00
Hier sehen wir direkt, dass sowohl die Ports als auch die Bridge eine MAC-Adresse haben. Interessanterweise hat nun die Bridge dieselbe MAC-Adresse wie P1. RouterOS setzt hier standardmäßig die MAC-Adresse der Bridge auf die MAC-Adresse des ersten Ports, welcher hinzugefügt wurde. Es empfiehlt sich, die MAC-Adresse der Bridge manuell zu setzen, damit sie sich nicht ändert und immer gleich bleibt, egal welche Ports der Bridge angehören.
/interface/bridge set Bridge admin-mac=36:2f:28:13:dc:25 auto-mac=no
Wie findet nun ein Ethernet-Frame sein Ziel? Die Ziel-MAC-Adresse ist im Header des Frames enthalten, es weiß also, wo es hin muss. Die Bridge ist nun verantwortlich dafür, das Paket von einem eingehenden (ingress) Port zu einem ausgehenden Port (egress) zu schieben. Welcher Port für welches Datenpaket verantwortlich ist, entnimmt die Bridge der Forwarding Information Base (FIB-Tabelle).
Diese Tabelle lernt anhand des Netzwerkverkehrs, welcher Port welche MAC-Adresse besitzt. Da wir noch keinerlei Traffic haben, müssen wir zuerst etwas im Netz stochern. Hier reicht ein Ping von Host1 zu Host2:
ping fe80::250:79ff:fe66:6801
Host 1 schickt das Ethernet-Frame (welches das Echo-Request ICMP-Paket vom Ping-Befehl kapselt) an seine an P1 angeschlossene Netzwerkverbindung. Daraufhin landet das Frame in der Bridge. Diese muss nun entscheiden, wohin das Frame weitergeleitet werden soll. Mit leerer FIB-Tabelle wird dies schwer, deshalb wird eine Kopie des Pakets an alle Ports geschickt.
Danach können wir uns mit dem Befehl /interface/bridge/host print die FIB-Tabelle ansehen.
Flags: D - DYNAMIC; L - LOCAL
Columns: MAC-ADDRESS, ON-INTERFACE, BRIDGE
# MAC-ADDRESS ON-INTERFACE BRIDGE
0 D 00:50:79:66:68:00 P1 Bridge
1 D 00:50:79:66:68:01 P2 Bridge
2 DL 36:2F:28:13:DC:25 Bridge Bridge
Die Bridge hat also dazugelernt, welche MAC-Adressen unter welchen Ports zu finden sind und kann so die folgenden Frames gezielt an einen Port weiterleiten.
Nun zu einem etwas komplexeren Beispiel. Vier Router sind miteinander verbunden, drei Hosts sind an unterschiedlichen Routern angeschlossen. Von einem Host zum anderen gibt es mehr als einen Weg.
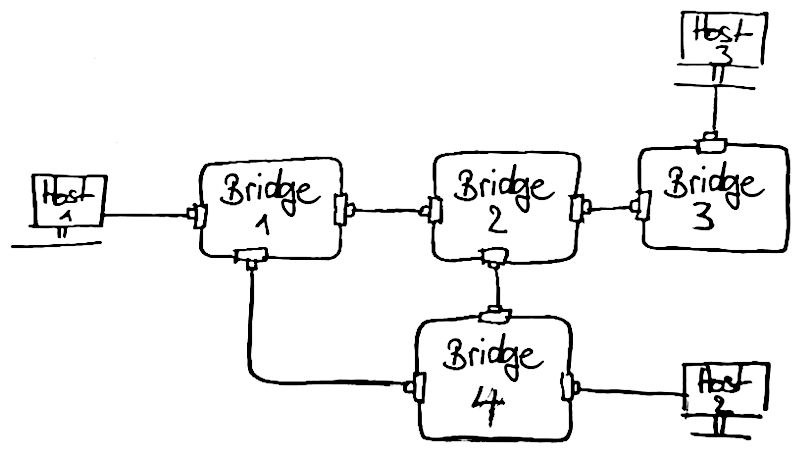
Nun entstehen plötzlich mehrere Probleme. Zum einen wird eine Art von Priorisierung benötigt, um den richtigen
Pfad zu definieren, welchen die Frames durch das Netz von der Quelle zum Ziel nehmen sollen. Zum anderen funktioniert das Anlernen der FIB-Tabelle nicht mehr. Es entsteht schnell eine Endlosschleife, wenn mehrere Router Pakete auf allen Ports verschicken.
Will Host 1 ein Frame an Host 3 schicken, landet es zuerst in Bridge 1. Diese kennt den Pfad zu Host 3 noch nicht und schickt eine Kopie des Frames an Bridge 2 und Bridge 4. Diese wiederum kennen Host 3 ebenfalls nicht und schicken wiederum Kopien weiter. Bridge 4 hat bisher von all dem nichts mitbekommen und schickt natürlich das Frame wieder an Bridge 1 und das Spiel wiederholt sich.
Spanning Tree Protocol
Willkommen zu STP, ein Router-Protokoll, das genau dies verhindert. Es stellt sicher, dass das Netz keine Schleifen enthält (und somit keine Frame-Lawine auslöst). RSTP ist eine Erweiterung von STP (abwärtskompatibel), die bei einer Neukonfiguration die alte Konfiguration so lange aufrechterhält, bis die neue verteilt wurde (keine Downtime). Das darunterliegende Austauschformat zwischen den Bridges nennt sich BPDU.
Doch was macht STP genau? Nehmen wir das Beispiel von oben: Es muss verhindert werden, dass Schleifen (wie die zwischen den Bridges 1, 2 und 4) entstehen und wenn es eine Schleife gibt, einzelne Verbindungen abschalten. Hierfür wird zuerst eine sog. Root Bridge
definiert, die als Anfang des Baumes fungiert. Welche das ist, wird dynamisch anhand der MAC-Adresse und der Priorität festgelegt: Die Bridge mit der kleinsten MAC-Adresse und der kleinsten(!) Priorität ist die Root-Bridge. An dieser Bridge wird nun der Baum aufgespannt. Wird eine Schleife erkannt, werden so lange Verbindungen deaktiviert, bis die Schleife aufgehoben ist. Umgekehrt werden Verbindungen aktiviert, wenn redundante Verbindungen entfernt werden. Welche Verbindungen das sind, wird anhand mehrerer Kriterien entschieden. Dazu zählen hauptsächlich die Verbindungskosten (meist definiert durch die Datenrate der Verbindung) und eine Priorität, die man selbst festlegen kann.
Im obigen Beispiel könnte Bridge 1 die kleinste MAC-Adresse haben und somit zur Root-Bridge gewählt werden. Anschließend wird eine Schleife zwischen Bridge 1, 2 und 4 erkannt. Da die Verbindung zwischen Bridge 2 und 4 nur ein wackeliger WiFi-Tunnel ist und Bridge 2 und 4 jeweils mit 10GBit über Glasfaser mit Bridge 1 verbunden sind, wird die Verbindung zwischen Bridge 2 und 4 deaktiviert. Wie genau die Wahl der Root-Bridge verläuft und wie STP bei einer Topologie-Änderung reagiert, ist hier recht ausführlich erklärt.
Beim Anlagen einer neuen Bridge ist RSTP aktiviert. Überprüfen kann man dies mit /interface/bridge print:
Flags: X - disabled, R - running
0 R name="Bridge" mtu=auto actual-mtu=1500 l2mtu=65535 arp=enabled
arp-timeout=auto mac-address=36:2f:28:13:dc:25 protocol-mode=rstp
fast-forward=no igmp-snooping=no auto-mac=no ageing-time=5m
priority=0x8000 max-message-age=20s forward-delay=15s
transmit-hold-count=6 vlan-filtering=no dhcp-snooping=no
port-cost-mode=long mvrp=no max-learned-entries=auto
Die Option protocol-mode steht auf rstp, also ist RSTP aktiv. Hier lässt sich auch die priority der Bridge ablesen. Mikrotik hat ein sehr nützliches Monitoring-Tool in RouterOS integriert, mit dem wir live den Status des kompletten Spanning Trees ansehen können. Hier ein Beispiel von zwei Bridges mit dem /interface/bridge monitor Bridge Befehl.
Bridge 1
state: enabled
current-mac-address: 36:2f:28:13:dc:25
root-bridge: yes
root-bridge-id: 0x8000.36:2f:28:13:dc:25
root-path-cost: 0
root-port: none
port-count: 3
designated-port-count: 2
fast-forward: no
-- [Q quit|D dump|C-z pause]
Bridge 1 wurde zur root-bridge, die root-path-costs sind somit 0. Auch der root-port (der Port, der zur Wurzel führt) steht auf none, da wir ja schon an der Wurzel sind. Der Spanning Tree in dieser Bridge besteht aus 3 Ports (port-count), zwei davon sind designated-ports, also Zweige
, die die Bridge verlassen und ebenfalls Teil des Netzes sind.
Bridge 2
state: enabled
current-mac-address: 36:2f:28:13:dc:26
root-bridge: no
root-bridge-id: 0x8000.36:2f:28:13:dc:25
root-path-cost: 2000
root-port: ether1
port-count: 3
designated-port-count: 1
fast-forward: no
-- [Q quit|D dump|C-z pause]
Bridge 2 hat als root-port ether1 eingetragen. Hier ist also Bridge 1 verbunden. Die root-path-costs sind auf 2000, dies ist der Preis
der Strecke bis zur Root Bridge. port-count steht auf 3, ein Port ist laut designated-port-count mit einem weiteren Zweig
verbunden. Aber so ist hier der dritte Port abgeblieben? Hier wurde offensichtlich eine Verbindung deaktiviert, um eine Schleife zu verhindern.
Edge Ports
Bis jetzt haben wir STP nur auf Sicht der kompletten Bridge betrachtet. Es ist aber auch möglich, das Verhalten für einzelne Ports innerhalb der Bridge anzupassen. Dafür ist die edge-Option gedacht. Wird ein Port als edge Port deklariert, werden keine BPDUs weitergereicht und auch keine entgegengenommen. Das ist praktisch, um den Übergang in ein komplett anderes Netz zu definieren oder wenn man sich absolut sicher ist, dass nach diesem Port keine weitere Bridge mehr kommt (ein Endgerät z.B.).
Paketgröße und Kompatibilität
Bis jetzt haben wir uns nur Bridges in Mikrotik-Hardware angesehen. Was aber, wenn ein Paket eine Bridge über einen Ethernet-Port verlässt und bei einem Juniper-Switch aufschlägt? Warum kommt der fremde Switch mit unserem Paket zurecht? Klar, ein Ethernet Frame auf Layer 2 ist standardisiert. Doch die Größe des Payloads (die eigentlichen Daten) ist variabel. Diese ist zwar im Header hinterlegt, doch wenn sie zu groß ist, kommt es zu Problemen.
Aus diesem Grund sollten wir uns den Begriff MTU (Maximum Transmission Unit) noch ansehen. Dieser Wert gibt an, wie groß der Payload eines einzelnen Ethernet-Frames im Netzwerk-Segment groß sein darf. Normalerweise steht dieser auf 1500, sind VLANs involviert, ist der Wert kleiner, da das VLAN Tag einen gewissen Platz vereinnahmt.
In den meisten Fällen ergibt es keinen Sinn, von einer MTU von 1500 abzuweichen, da das komplette Netzwerk-Equipment damit kompatibel sein muss (zumindest innerhalb einer Broadcast-Domain). Auch wenn 1500 Bytes für heutige Verhältnisse recht klein ist und entsprechend viel Overhead mitbringt, macht es aus Kompatibilitätsgründen weiterhin Sinn, daran festzuhalten. Stellt man die MTU absichtlich höher (auf 9000 z.B.), spricht man von Jumbo Frames.
Nun gibt es unterschiedliche MTU-Werte, mit unterschiedlichen Namen, die alle eine leicht unterschiedliche Aufgabe haben. Zum Verständnis hier einmal alle aufgelistet:
- mtu: Die Layer 3 MTU des Ports bzw. der Bridge. Wenn mtu auf
autosteht, wird die MTU automatisch gesetzt, und zwar auf den niedrigsten Wert aller Interfaces in der Bridge. Hat die Bridge noch keine Ports zugewiesen, wird sie auf1500gesetzt. - l2mtu: Die L2MTU wird automatisch anhand der MTU gesetzt und ist nur zu informativen Zwecken da (read only). Sie gibt die maximale Frame-Größe (Layer 3 MTU) + allen Overhead wie VLAN-Tags, aber ohne den MAC-Header an.
- actual-mtu: Ebenso ein rein informativer Wert, der die echte MTU angibt. Dies ist der reale MTU-Wert, der verwendet wird.
- path-mtu: Die ermittelte MTU, mit der von der Quelle bis zum Ziel gearbeitet werden kann, ohne dass Frames zerschnitten werden müssen (fragmentation).
Performance
An der MTU zu drehen, ist eine Möglichkeit, den Overhead der Paketheader zu minimieren. Dies macht aber nur dann Sinn, wenn die verwendete Hardware bekannt und kompatibel ist. Die Anbindung eines Cluster-Nodes an einen Backup-Server profitiert von Jumbo Frames und die Übertragung des nächtlichen Backups verläuft viel performanter.
Dies ist allerdings längst nicht die einzige Stellschraube, um ein Netzwerk möglichst performant zu machen. Kennt man seine Hardware und weiß, wie RouterOS arbeitet, kann man so einiges aus einem Router herausholen bzw. Bottlenecks erkennen und beheben.
Fast Forward
Eine Option ist fast-forward. Sind nur exakt 2 Ports in einer Bridge (und ein paar weitere Bedingungen erfüllt), kann fast-forward aktiviert werden, um den Traffic noch effizienter zu routen, da einige Checks übersprungen werden können. Und auch das Lernen der MAC-Adressen ist nicht nötig, da es nur ein Ziel gibt.
Hardware Offload
Noch spannender wird es mit dem Thema Hardware Offloading. Hat der Mikrotik Router ein (oder mehrere) Switch-Chips verbaut, können diese einige Aufgaben der Bridge übernehmen. Welche Aufgaben das sind, hängt ganz von den Fähigkeiten der Switch-Chips ab. Ob und welche verbaut wurden, lässt sich mit /interface/ethernet/switch print prüfen. Bei meinem RB2011UiAS-2HnD sieht das bspw. so aus:
Columns: NAME, TYPE
# NAME TYPE
0 switch1 Atheros-8327
1 switch2 Atheros-8227
Es sind also zwei Switch-Chips verbaut. Ein Atheros-8327 und ein Atheros-8227. Wirft man einen Blick in die Tabelle der Switch-Chip-Features sieht man, dass beide Chips einiges an Features wie eine VLAN-Tabelle und eine Host-Tabelle mitbringen, doch der 8327 auch Firewall-Regeln verarbeiten kann.
Nun fehlt nur noch eine Information: Wie sind denn die Switch-Chips konkret verkabelt? Und an welchem Port kann ich nun auf welchen Switch-Chip zugreifen? Hier stellt Mikrotik einen genialen Service bereit: Zu jedem Produkt gibt es auf der Website (unter Downloads) ein Block-Diagramm, das den internen Aufbau des Routers abbildet. Für den oben genannten Router sieht dieses so aus:
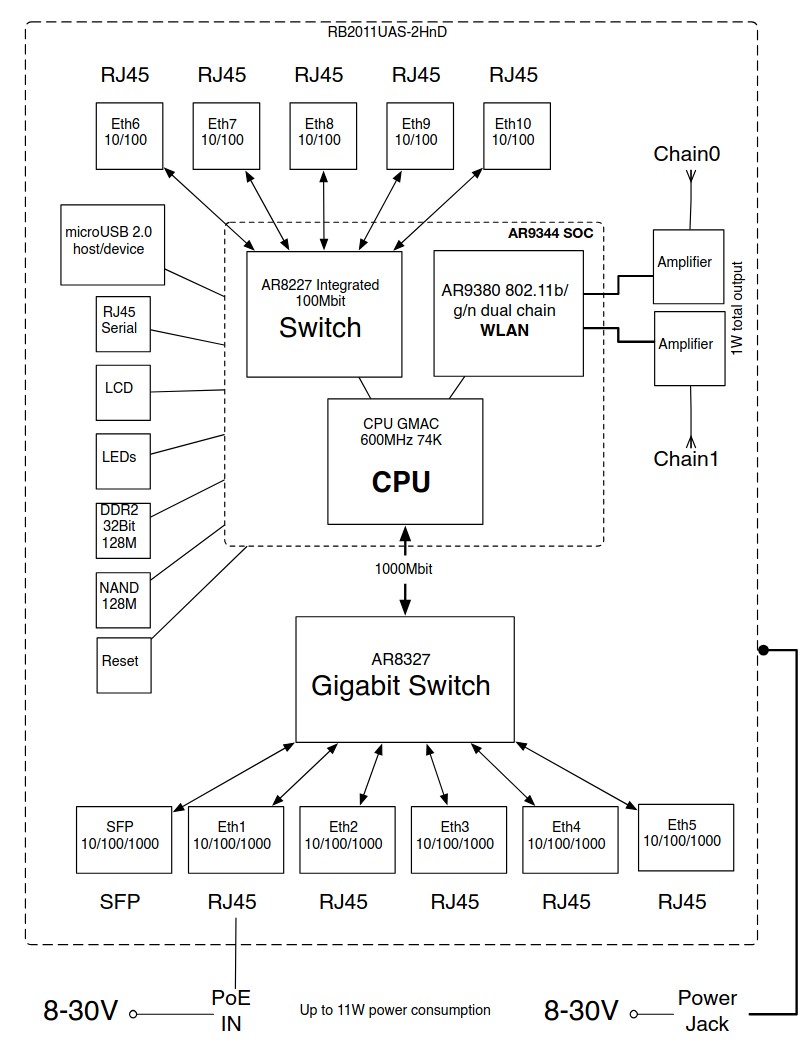
Hieraus können wir nun einiges ablesen. Zum einen sieht man, dass der AR8227 Switch-Chip eigentlich kein eigenständiger Chip ist, sondern zusammen mit der CPU und dem WLAN-Modul in einem einzigen SOC steckt. Die Geschwindigkeit der Ports 6 bis 10 an diesem Switch-Modul
beträgt zudem nur max. 100 MBit. Der AR8327 allerdings ist ein eigenständiger Chip, der über eine 1GBit-Leitung mit der CPU verbunden ist. Und auch die Ports 1 bis 5, sowie der SFP-Port kann 1GBit. Dies sind also die begehrten Ports. Eine Wetterstation hingegen würde ich hier eher an Port 6 anschließen.
Weiter wird klar, wenn Traffic von Port 1 nach Port 6 fließt, muss dieser zwangsläufig durch die 1GBit-Anbindung an die CPU, über den integrierten Switch raus nach Port 6. Interessant wird es nun, wenn Traffic von Port 1 nach Port 2 fließt. Muss der Traffic durch die 1GBit-Verbindung an die CPU, um dann wieder zurück an den Switch-Chip nach Port 2? Oder kann der Switch-Chip dies eigenständig? Und wenn ja, in welchen Fällen muss der Traffic dennoch durch die CPU?
Hier kommt Hardware Offloading ins Spiel. Im ersten Fall (Traffic von Port 1 nach Port 6) gibt es keinerlei Möglichkeit, etwas zu optimieren. Der Traffic muss durch alles durch. Im zweiten Fall hingegen (Traffic von Port 1 nach Port 2) gibt es Potenzial für Optimierung. Wenn wir Hardware Offloading für beide Ports aktiviert haben (die unscheinbare hw Option), versucht RouterOS sein Möglichstes, Last auf den Switch-Chip auszulagern. Je nach Feature-Set des Switch-Chips und Einstellungen klappt das oder auch nicht. Ob es klappt, sieht man an dem H-Flag in der Interface-Liste. Kann der Switch-Chip keine VLAN-Tabelle, sind aber VLANs aktiv, muss weiterhin die CPU übernehmen. In einem solchen Fall verschwindet das H-Flag, auch wenn Hardware Offloading aktiviert ist.
Wer es ganz genau wissen will, welchen Weg die Frames/Pakete in RouterOS unter welchen Bedingungen nehmen, sollte einen Blick in die Dokumentation werfen, hier ist der Packet Flow visuell aufbereitet (dazu gleich mehr).
Übernimmt also der Switch-Chip Routing- und Switching-Aufgaben, kann man das volle Potenzial ausschöpfen. Man spricht hier auch von Wire Speed
, hat also die vollen 1GBit auf jedem Port (parallel!) zur Verfügung. Wie viel der komplette Router (in verschiedenen Konstellationen) schafft, gibt Mikrotik ebenfalls zu jedem Produkt auf der Website an. Es lohnt sich also, die eigene Hardware zu kennen, um diese optimal einzusetzen. Zudem können so teure
Settings viel besser vermieden werden, um so Bottlenecks aus dem Weg zu gehen.
Layer 3 Hardware Offloading
Einige der neueren Modelle haben Switch-Chips, die auch Layer 3 können. Dies ist allerdings nochmal ein komplexeres Thema und nur in den großen CRS Switchen verfügbar. Einen guten Einblick gibt dieser Post im Mikrotik-Forum.
Firewall
Bis jetzt war eine Bridge dem User gegenüber transparent
, tauchte also in einem Traceroute nicht auf. Grund dafür ist, dass eine Bridge auf Layer 2 (MAC-Adressen) arbeitet. Es ist allerdings möglich, einer Bridge eine IP zu geben, um auf Layer 3 (IP-Adressen) zu operieren. So ist die Bridge nach außen sichtbar, ähnlich einem Switch. Aber auch IP-basierte Services lassen sich dann auf der Bridge anbieten. Ein klassisches Beispiel hierfür ist ein DHCP-Server. Aber auch eine IP-Firewall kann dann IP-Pakete filtern.
Das ist alles ziemlich abstrakt. Um das zu verstehen, müssen wir uns zuerst ansehen, wie ein IP-Paket bzw. ein Ethernet-Frame durch den Router fließt. Machen wir hierfür ein Beispiel mit zwei Bridges und drei Hosts.
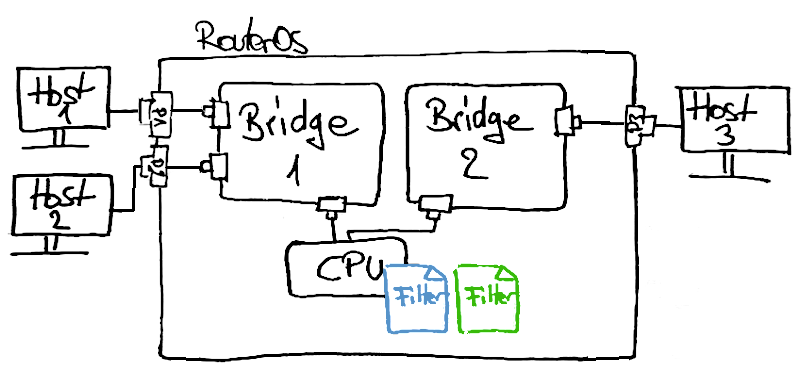
Im Bild zu sehen sind zwei Bridges (Bridge1 und Bridge2). Host 1 und Host 2 sind an Bridge1 angeschlossen, Host 3 an Bridge2. Neu dazugekommen ist nun ein Detail: die CPU. Alle Bridges haben immer einen weiteren CPU-Port
zugewiesen, zu dem ebenfalls Traffic fließen kann und von dem Traffic empfangen werden kann. Was es mit den beiden Filter-Tabellen auf sich hat, wird im Folgenden klar.
Konfigurieren wir nun die beiden Bridges mit entsprechenden Ports wie anfangs schon beschrieben und vergeben IPs an Host 1 bis 3 (müssen nicht im selben Netzwerk sein), können wir von jedem Host jeden anderen erreichen. Doch warum ist das so?
Packet Flow
Wie gerade schon erwähnt, liefert die Mikrotik Dokumentation im Kapitel Packet Flow in RouterOS einen detaillierten Einblick in den Paketfluss. Die vielen Schaubilder wirken abschreckend und viele davon können wir ignorieren. Doch um zwei kommen wir nicht drumherum. Hier zu sehen, die Übersicht über den kompletten Paketfluss.
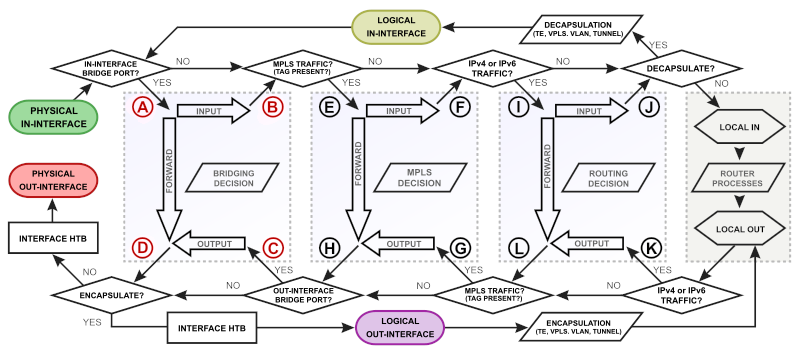
Dies mag etwas überwältigend wirken, doch große Teile davon können wir anfangs ignorieren, an einer Stelle müssen wir aber noch weiter ins Detail.
Gehen wir unser obiges Setup beispielhaft durch. Host 1 sendete einen Ping an Host 2. Beide sind in derselben Bridge1 angesiedelt. Haben wir Hardware Offloading aktiviert und die Bridge kennt bereits beide Hosts, fließt das Ping-Paket vom physikalischen In-Interface (P1, dunkelgrün im Schaubild) direkt zum physikalischen Out-Interface (P2, dunkelrot im Schaubild). Das ist natürlich der Best Case. Doch gehen wir im Folgenden davon aus, dass Hardware Offloading ausgeschaltet ist. Moderne Switch-Chips übernehmen noch weitere Teile des Packet Flows, doch welche das genau sind, hängt vom Chip ab und RouterOS trifft diese Entscheidung selbstständig -- ist also hier nicht relevant.
Das Ping-Paket kommt also am physikalischen Port P1 an und landet im linken hellblauen Kasten (Bridge1), gekennzeichnet mit einem (A). Da das Paket nach P2 soll und dieser Port ebenfalls in Bridge1 angesiedelt ist, wird es direkt per Forward
aus der Bridge befördert (gekennzeichnet mit (D)) und landet schlussendlich bei Host 2.
Was nun, wenn wir einen Ping von Host 1 nach Host 3 absetzen? Hier landet das Paket wieder im ersten hellblauen Kasten (Bridge1), doch hier kann es nicht direkt an den physikalischen Port P3 weitergeleitet werden, da P3 nicht in derselben Bridge ist. Das Paket wandert also über Input
aus der Bridge (gekennzeichnet mit (B)) und nach dreimal No
in Local In (grauer Kasten ganz rechts). Hier entscheidet nun die CPU, was mit dem Paket geschieht. Da es für eine andere Bridge gedacht ist, wird das Paket über Local Out weiter auf die Reise zur Ziel-Bridge (Bridge2) geschickt. Hier landet es nach ein paar weiteren Fallentscheidungen in Output
von Bridge2 (gekennzeichnet mit (C)) und schlussendlich beim Port P3. Achtung, im Schaubild ist das jetzt nicht mehr Bridge 1 sondern Bridge 2! Wer sich hier schwer tut, dem sei der Vortrag von Herry Darmawan zu empfehlen.
Diese Beispiele erklären, warum und wie Traffic zwischen Bridges fließt. Jetzt können wir uns anschauen, wie wir hier in den Paketfluss eingreifen können.
Bridge Firewall
Dafür müssen wir den ersten hellblauen Kasten etwas genauer betrachten (die Ein- und Ausgänge A bis D entsprechen den im hellblauen Kasten des vorherigen Schaubilds).
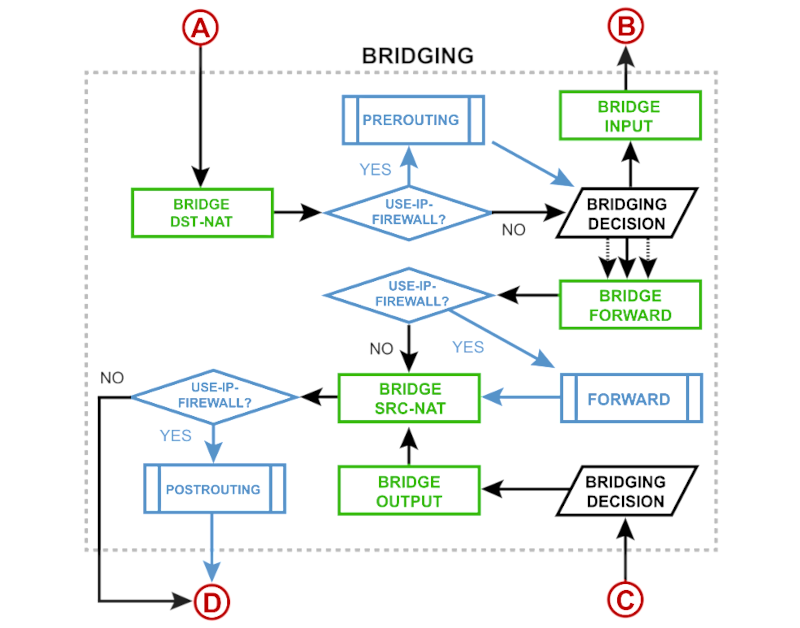
Wir haben zwei Möglichkeiten, Pakete zu filtern: In der Bridge-Firewall (die grünen Kästen im Schaubild) und in der normalen IP-Firewall (die blauen Kästen im Schaubild). Wir fokussieren uns zunächst auf die Bridge-Firewall, können also alle blauen Kästen ignorieren. Wir operieren ausschließlich auf Layer 2 (analog zu ebtables bzw. der bridge
family in nftables), IP-Adressen oder Protokolle sind also nicht relevant.
Die Bridge-Firewall greift auf verschiedene Filter-Tabellen zu, die sich in /interface/bridge/filter und /interface/bridge/nat befinden. Die Tabellen gelten für alle Bridges gleichermaßen.
Kommt also ein Paket über (A) in die Bridge, wird zuerst DST-NAT konsultiert und die Regeln darin angewendet. Anschließend muss die Bridge eine Entscheidung treffen. Über die FIB-Tabelle wird entschieden, was mit dem Paket geschieht. Wie am Anfang des Artikels aufgezeigt, enthält die FIB-Tabelle das Mapping von MAC-Adresse zu Port. Ist die Ziel-MAC-Adresse in der FIB-Tabelle zu finden, wird das Paket weiter über die Forward-Tabelle weitergereicht. Ist die MAC-Adresse unbekannt, wird eine Kopie des Pakets an alle bekannten Ports an die Forward-Tabelle gereicht und eine weitere Kopie an die Input-Tabelle (damit die anderen Bridges ebenfalls von dem Paket Kenntnis nehmen können).
Kann das Paket nicht in der gleichen Bridge an den Zielport weitergeleitet werden, landet es in Input und wandert dann aus der Bridge. Trifft das Paket nach langer Reise bei (C) wieder in einer Bridge ein, findet analog zum eingehenden Paket eine Entscheidung statt und wandert dann über Output und SRC-NAT schlussendlich am physikalischen Ziel-Interface.
In jede dieser Bridge-Firewall-Tabellen können wir nun Filter-Regeln platzieren, die an gerade beschriebener Stelle zur Anwendung kommen. Wichtig hierbei ist zu beachten, dass alle Tabellen sequenziell von oben nach unten abgearbeitet werden. Je nachdem welche Regel zutrifft und welche Aktion darauf folgt, kann es vorkommen, dass nicht alle Regeln abgearbeitet werden und das Paket vorzeitig abgelehnt bzw. erlaubt wird. Auch wichtig: Anders als bei iptables/nftables ist die default policy auf accept, sind also keine Regeln angegeben oder das Paket hat es unbeschadet durch alle Regeln geschafft, ist es automatisch akzeptiert und wandert weiter. Machen wir ein paar Beispiele.
Kommunikation von Host 1 nach Host 2 unterbinden
Wir wollen den Paketfluss von Host 1 nach Host 2 unterbinden. Da beide Ports in derselben Bridge angesiedelt sind, verlassen wir die Bridge nicht und wir können in der Forward-Tabelle unsere Regel platzieren.
/interface/bridge/filter
add chain=forward in-interface=P1 out-interface=P2 action=drop
Kommt das Paket von P1 und will nach P2, führen wir die Aktion drop aus, welche das Paket an dieser Stelle verwirft.
Bridges isolieren
Bridges können normalerweise untereinander Pakete austauschen. Wie das geht, haben wir weiter oben gesehen. Wollen wir unterbinden, dass Pakete eine Bridge verlassen, müssen wir den Ausgang blockieren.
/interface/bridge/filter
add chain=input action=drop
Dies machen wir, indem wir alle Pakete, die in Input der Bridge-Firewall landen und über (B) weiter wollen, verwerfen. Traffic, der innerhalb der Bridge bleibt (Kommunikation zwischen Host 1 und 2), fließt weiterhin über Forward und ist somit davon nicht betroffen.
Admin Packet Mark
Angenommen, an Port P1 hat ein Administrator seinen PC angeschlossen. Dieser möchte (anders als die anderen) alle Hosts erreichen. Wir können all seine Pakete mit einem admin
-Tag versehen, so dass er an der Input- und Output-Tabelle freies Geleit bekommt.
/interface/bridge/filter
add chain=input in-interface=P1 action=mark-packet packet-mark=admin
add chain=output out-interface=P1 action=mark-packet packet-mark=admin
add chain=input packet-mark=admin action=accept
add chain=output packet-mark=admin action=accept
Über Packet Marks markieren wir den kompletten eingehenden und ausgehenden Traffic von P1 mit der Markierung admin
. Anhand dieser können wir zu einem späteren Zeitpunkt (auch dann noch, wenn das Paket in einer anderen Bridge gelandet ist) die Pakete identifizieren und entsprechen akzeptieren.
IP Firewall
Nun aber steht die Frage im Raum, wie man Pakete auf Layer 3 filtern kann, wenn sie die Bridge nicht verlassen (eine Bridge ist und bleibt ein Layer 2 Konzept). Hierzu gibt es das globale Flag use-ip-firewall in den Bridge-Settings, welches die blauen Kästen im obigen Schaubild aktiviert. Ist es aktiviert, gibt es möglicherweise kein Hardware Offloading mehr, aber wir können Pakete auf Layer 3 filtern. Hierzu wird die normale Firewall unter /ip/firewall verwendet. Und besser noch, beide Firewalls können kombiniert werden. Hierzu ein Beispiel.
Zuerst aktivieren wir die IP-Firewall in der Bridge.
/interface/bridge/settings
set use-ip-firewall=yes
In unserem Beispiel setzen wir auch in der forward Tabelle der Bridge-Firewall die admin
-Markierung für das P1-Interface.
/interface/bridge/filter
add chain=forward out-interface=P1 action=mark-packet packet-mark=admin
Nun können wir als Beispiel ICMP-Traffic für Pakete mit der admin
-Markierung erlauben. Packet Marks aus der Bridge-Firewall sind also auch in der IP-Firewall verfügbar. So kann der Administrator an P1 alle anderen Hosts in seiner Bridge pingen.
/ip/firewall/filter>
add chain=forward packet-mark=admin protocol=icmp action=accept
add chain=forward action=drop
VLAN
Ein weiteres großes Thema ist natürlich 802.1Q bzw. VLAN. Ein solch komplexes Thema ist einen eigenständigen Artikel wert und ich habe es deshalb hier ausgelassen.
Dies waren jetzt die Basics zu Mikrotik Bridges. Das meiste davon kann man aber auch auf Linux Bridges übertragen, die in den verschiedensten Szenarios Anwendung finden. Docker nutzt Linux Bridges zusammen mit iptables, um die Container zu Netzwerken zusammenzuschließen. Jeder, der bereits mit Kubernetes, OpenShift oder OpenStack in Berührung gekommen ist, hat bestimmt schon die ein oder andere Bridge gesehen. Es ist und bleibt eine zentrale Komponente moderner Netzwerke.
Eine abschließende Frage steht noch im Raum: Warum macht Mikrotik bzw. RouterOS das alles so transparent und detailliert? Warum sich überhaupt mit Bridges und Layer 2 beschäftigen? Andere Hersteller wie bspw. UniFi abstrahieren die meisten Details weg, so dass der Endnutzer eine einfachere Konfiguration vorfindet. Wenn es dann allerdings ins Detail geht (so sehen die Tipps
zur Optimierung des Traffics aus), steht man schnell ratlos da. Da hilft dann meist nur, das Problem mit Geld zu bewerfen. Ich denke allerdings, der entscheidende Vorteil ist, dass RouterOS auf vielen verschiedenen Hardware-Plattformen läuft. Es gibt unzählige Mikrotik Produkte, auf denen (mit ein paar wenigen Ausnahmen) überall das gleiche RouterOS läuft. Mein 12 Jahre alter RB2011UiAS-2HnD läuft mit der neuesten RouterOS Version 7.16.2 (vom 26.11.2024). Bei all der unterschiedlichen Hardware einen gemeinsamen Nenner finden, wird schwer, aber ist so natürlich auch nicht nötig. So kann Mikrotik Profi-Hardware zu Consumer-Preisen anbieten und wird zugleich zur Hacker Friendly
Platform, mit der man das Potential der Hardware optimal ausschöpfen kann.
Vielen Dank an @mezzo und @nougad für den wertvollen Input und das Korrekturlesen. Ebenso mit kleinen Verbesserungen beigetragen haben @njumaen und @df4or.