Active Browsing, Teil 1
ProgrammiersprachenWer bei meinem Vortrag mit dem Titel Fix the web with Greasemonkey dabei war, weiß was gemeint ist. Für alle anderen ein kleiner Abriss: Das Web liefert uns aufbereitete Daten in einer Form, die der Ersteller festlegt. Oft ist es aber so, dass man nur an einer bestimmten Information interessiert ist und alles andere am liebsten ausblenden würde oder auf eine andere Art und Weise dargestellt bekommen möchte. Mechanismen, die dazu beitragen, die Informationen so darzustellen, wie es einem selbst am besten gefällt, nennt man Active Browsing. Mittlerweile gibt es einige Tools, um sich das Surfen etwas zu personalisieren und nach den eigenen Wünschen zu formen.
Mit dem schon erwähnten Greasemonkey - einem Firefox-Addon - kann man durch einfache Javascript-Dateien die Darstellung umgestalten, in dem man in den DOM-Baum eingreift. Ein anderes Beispiel ist die Leseansicht von Firefox, welches den eigentlichen Content der Seite hervorhebt.
Diese Tools vereinfachen das Surfen ungemein, aber es gibt oft genug Situationen, wo man regelmäßig eine bestimmte Information auf einer Webseite abfragen will, bspw. den Flottenstatus bei einem Onlinespiel oder ob jemand neue Artikel bei eBay eingestellt hat. Für gewöhnlich geht man hier alle paar Stunden auf die Seite, loggt sich ein, hangelt sich durch ein paar Menüs und sucht die Information, die meistens nur aus einer Zahl oder einer Liste bestehen, heraus. Wie praktisch wäre es doch, wenn solche Seiten einen RSS-Feed oder eine andere API anbieten würden, damit man immer zur richtigen Zeit mit den entsprechenden Informationen versorgt werden würde. Dies ist allerdings in den seltensten Fällen so. Eine bessere Möglichkeit muss also her!
Hinweis: Da ich nach der Springerlink Aktion (eingeweihte wissen Bescheid) etwas vorsichtig geworden bin was Web-Automatismus
angeht, soll das folgende Beispiel nur das Konzept verdeutlichen und dient NICHT zur eins zu eins Nachahmung. Deshalb stelle ich auch nicht den kompletten Code online, sondern nur die einzelnen Stücke separat. Zudem wird das Verfahren oft missbräuchlich verwendet. Grundsätzlich ist jeder selbst für sein Handeln verantwortlich und sollte mit gesundem Menschenverstand und Rücksicht auf den Webseitenbetreiber vorgehen, denn dieser stellt schließlich den Service bereit und trägt den Traffic.
Um mit dem Nachfolgenden etwas anfangen zu können, muss man kein Ruby können und auch kein Linux verwenden, es soll nur das Konzept beschrieben werden. Ähnliche Tools und Bibliotheken gibt es in fast jeder Sprache.
So, nun also zum Thema! Weiter oben habe ich die Problematik mit den immer wiederkehrenden Schritten, um an eine bestimmte Information zu kommen, schon angesprochen. Diesen Umstand wollen wir vereinfachen. Als Beispiel nehme ich das Portal textbroker.com, auf dem Autoren Texte für Geld schreiben können und Kunden Anfragen für Texte stellen können. Leider gibt es mehr Autoren als Kunden, so sind die meisten Aufträge schon nach ein paar Minuten nach der Einstellung vergeben. Sprich, man muss entweder Glück haben und im richtigen Moment die Stellenbeschreibung anschauen oder eben alle paar Minuten das folgende Szenario abspulen:
Auf die Startseite gehen und sich anmelden. Zum Glück speichert Firefox nach dem ersten Mal ein Cookie und dieser Schritt muss nur einmal am Tag gemacht werden. Dann auf Aufträge Zeigen
und anschließend auf den Button Suche starten
klicken. Nun bekommt man alle verfügbaren Aufträge angezeigt. Da man meist nur an bestimmten Aufträgen interessiert ist, und die Liste alle verfügbaren Aufträge anzeigt, muss man diese nach Änderungen durchsuchen und kann sich dann entscheiden, ob man den Auftrag annehmen will oder nicht.
Diesen Vorgang wollen wir automatisieren, aber nicht im Browser, sondern mit einem externen Programm. Die Idee ist, dass sich das Programm selbständig in regelmäßigen Abständen auf der Webseite einloggt, die Liste der verfügbaren Aufträge holt und diese dem User über die Notification Area der Schnellstartleiste (unter Windows wird das meines Wissens SysTray genannt), als Notification (Sprechblase) anzeigt. Das Ergebnis soll so aussehen:
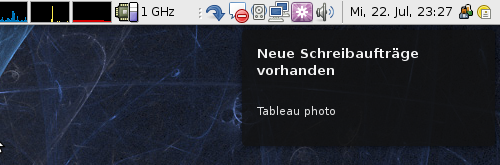
Um dies ohne händisches Parsen von XML Dateien oder umständliche wget/curl Aufrufe zu lösen, gibt es im Ruby Umfeld einige interessante Projekte. Eines davon nennt sich mechanize, das die Interaktion mit Webseiten um einiges vereinfacht. So wird dem Programmierer beispielsweise das Cookie-Handling komplett abgenommen und auch das Parsen der HTML-Seiten ist erschreckend simpel. Ein weiteres tolles Projekt ist ruby-libnotify, welches ein Wrapper für libnotify implementiert, um Betriebssystem Notifications darzustellen.
Mit diesen beiden Helfern wollen wir ein Programm zusammennageln, das uns immer die neusten Jobangebote anzeigt. Wie dies funktioniert, erfahrt ihr im nächsten Blogeintrag :)