Programmierwettbewerb 1: Auswertung
TL;DR: Zuerst einmal möchte ich mich bei allen bedanken die mitgemacht haben! Insgesamt habe ich sieben Einsendungen in den unterschiedlichsten Programmiersprachen erhalten, das hat mich sehr gefreut!
Mitgemacht haben (sortiert nach Abgabedatum):
Aaron Fischer (Ruby, download)
Klaus Breyer (PHP, download)
Thomas Monninger (Bash, download)
Florian Eitel (Ruby, download)
Wolfgang Kuhl (Java, download)
Stefan Nitz (PHP, download)
Marcel Steinle (C#, download)
Robert Giczewski (Java, download)
(Alle Programme herunterladen)
Die Aufgabe
Die gestellte Aufgabe haben alle erfolgreich gemeistert. Ziel war es, einen kleinen Transformator zu schreiben, der Text in eine strukturierte Form bringt. Dabei gab es verschiedene Ansätze, die meisten verwendeten reguläre Ausdrücke um den Text zu analysieren, aber es gab auch andere interessante Lösungen. (Bei den Codeausschnitten habe ich mich aufs Wesentliche beschränkt und unnötiges wie das Einlesen der Datei oder die Ausgabe oftmals weggelassen. Wer den kompletten Code sehen will, klickt auf den angegebenen Link)
Auswertung
Klaus
- Sprache: PHP
- LOC: 10
Schon nach ein paar Stunden erhielt ich seine Lösung. Er verwendete die preg_split()-Funktion um mit Hilfe eines regulären Ausdrucks die Aufzählungszeichen als Trenner zu identifizieren. So zerlegte er den kompletten Eingabetext in einem Rutsch. In einer Schleife entfernte er dann die Zeilenumbrüche durch Leerzeichen. Zum Testen stellte er gleich noch ein Eingabeformular bereit.
$text = $_POST["text"];
$array = preg_split("/((\\-\\s)|(\\>>\\s)|(\\d\\.\\s)|(\\so\\s))+/", $text, -1, PREG_SPLIT_NO_EMPTY);
foreach($array as $key => $value) {
$array[$key] = trim(str_replace("\\n", " ", $value));
}
echo "<<p>>";
foreach($array as $key => $value) {
echo " * " . $value . "<<br />>";
}
echo "<</p>>";
Kleine Erklärug zum RegExp-Ausdruck: die \s fangen alles auf, was im Entferntesten nach Leerzeichen aussieht, das \d steht für eine Ziffer. Die runden Klammern markieren Anker um später darauf zugreifen zu können (was hier aber nicht verwendet wurde) oder gruppieren Ausdrücke.
Thomas
- Sprache: Bash
- LOC: 23
Auch sehr schnell war Thomas mit seiner Bash-Lösung. Auch hier wurde mit regulären Ausdrücken gearbeitet, um zuerst die Leerzeichen und leere Aufzähungspunkte wegzuschneiden (\d), dann nach den Aufzählungspunkten zu suchen und durch Sternchen zu ersetzen (\g) und zum Schluss noch doppelte Sternchen und Ziffern zu entfernen. Wie es unter Linux üblich ist wurde hier sed verwendet. Als temporärer Zwischenspeicher mussten Dateien herhalten.
if [ $# -eq 1 ]
then
sed -e "/^[ \\t]*$/d" -e "s/\\(^[ \\x9]*\\([->>o]\\|\\([0-9]\\+[\\.]*\\)\\)\\)/"*"/g" -e "s/^\\*\\([ ]*\\)/"*" /g" -e "s/^[ \\x9]\\+/""/g" $1 > tmp.tmp
while read zeile; do
if [ "${zeile:0:1}" = "*" ]
then
if [ -n "$tmp1" ]
then
echo "$tmp1" >> tmp2.tmp
tmp1="$zeile"
else
tmp1="$zeile"
fi
else
tmp1="$tmp1"" ""$zeile"
fi
done < tmp.tmp
cat tmp2.tmp > ergebnis
rm tmp.tmp
rm tmp2.tmp
else
echo "Usage: thomas.sh <<input-file>>"
fi
Wer die Syntax von Bash nicht kennt: Um Teile aus einem String herauszufiltern, kann man ${zeile:0:1}
verwenden (ähnlich wie substring() in anderen Sprachen). Das -n beim if prüft ob der String NICHT leer ist (NonZero).
Florian
- Sprache: Ruby
- LOC: 2
Sehr kompakt formuliert und ohne jeglichen extra Ballast: Der Eingabetext wird von der Standardeingabe gelesen, drei reguläre Ausdrücke darauf angewendet und wieder auf der Standardausgabe ausgegeben. Der Ablauf ist ähnlich wie bei Thomas: Im ersten Schritt werden die Aufzählungspunkte durch Sternchen ersetzt und die Leerzeichen entfernt, im zweiten Schritt werden die Zeilenumbrüche behandelt. Das letzte gsub() behandelt den Spezialfall, falls eine Ziffer alleine in einer Zeile steht. Dadurch, dass die Aufzählungspunkte extra definiert sind, lässt sich der Transformator sehr schnell erweitern!
bullets = %w( [[:digit:]]+\\. - >> o )
puts STDIN.read.gsub(/(^\\s*(#{ bullets.join("|") })\\s+)/, "* ").gsub(/\\n(?!\\*)\\s*/, " ").gsub(/^\\* \\s+/, "* ")
Für die, die noch nie mit Ruby gearbeitet haben: Das %w erzeugt ein Array, der Separator hier ist das Leerzeichen. gsub() ist äquivalent zum preg_replace() von PHP.
Wolfgang
- Sprache: Java
- LOC: 26
Einen ganz anderen Weg hat Wolfgang mit seiner Java-Lösung gewählt. Ganz ohne reguläre Ausdrücke hat er das Problem mit Zeichenvergleiche gelöst. Von jeder Zeile werden zuerst die Leerzeichen am Anfang und am Ende entfernt. Diese Strings werden dann dahingehend überprüft ob das zweite Zeichen ein Punkt oder ein Leerzeichen ist, also ob es sich um ein Aufzählungspunkt handelt. Wenn das der Fall ist, wird der Rest zusammen mit dem Sternchen an die Ausgabe angehängt. So ist der Code auch für alle anderen Typen von Aufzählungszeichen vorbereitet, doch wenn das Aufzählungszeichen aus zwei Zeichen besteht (z.B. 14.
oder #>
) oder ein einzelner Buchstabe am Anfang einer neuen Zeile steht, funktioniert das Programm nicht mehr richtig.
public String parseToWikiString(File file) throws IOException{
try {
br = new BufferedReader(new FileReader(file));
zeile = br.readLine();
while (zeile != null) {
if(!zeile.equals("")){
zeile = zeile.trim();
if(zeile.charAt(1) == "." || zeile.charAt(1) == " "){
output = output + "\\r\\n * ";
zeile = zeile.substring(2).trim();
output = output + zeile;
}else
output = output + zeile ;
}
zeile = br.readLine();
}
br.close();
return output;
}catch (FileNotFoundException e){
e.printStackTrace();}
return "Fehler beim Parsen";
}
Stefan (PHP)
- Sprache: PHP
- LOC: 11
Stefan hat es sich mit seiner Lösung einfach gemacht. Er nahm wiederum die preg_split()-Funktion zur Hilfe um die Aufzählungspunkte zu finden und an den Stellen zu trennen. Da der Browser (wenn man denn das PHP-Skript auf einem Webserver ausführt) nur ein Leerzeichen zulässt und Zeilenumbrüche ebenfalls ignoriert, kommt seine Lösung ganz ohne Entfernung dieser aus. Klever gemacht :-)
$keywords = preg_split("/- |[0-9]\\.|>>| o /", $txt);
for ($x = 1; $x < sizeof($keywords); $x++) {
echo "* ".$keywords[$x]."<br>";
}
Marcel
- Sprache: C#
- LOC: 28
Auch eine C#-Variante wurde von Marcel eingereicht! Schön dokumentiert und übersichtlich. Der Eingabetext wird zuerst an den bekannten Kommentarzeichen gesplittet, von den einzelnen Ergebniszeilen die Leerzeichen entfernt und mit einem Stern ausgegeben. Leider wurde nicht beachtet, dass die Aufzählungspunkte immer am Anfang stehen müssen. So gibt es schnell Fehler, wenn beispielsweise ein HTML-Tag im Text steht oder der 70. Geburtstag der Großeltern gefeiert wird.
StreamReader sr = new StreamReader(args[0]);
StreamWriter sw = new StreamWriter(args[1]);
Regex split = new Regex("-| o |> |[1-99].", RegexOptions.Multiline | RegexOptions.Compiled);
Regex whitespace = new Regex(@"\\s+|\\s+\\n|\\n|\\r\\n");
while (!sr.EndOfStream)
input += Convert.ToString((char)sr.Read());
intermediate = split.Split(input);
for (int i = 1; i < intermediate.Length; i++)
{
sw.WriteLine("* " + whitespace.Replace(intermediate[i], " ").Trim());
}
sw.Close();
Robert
- Sprache: Java
- LOC: 108
Auch diese Java-Lösung kommt ganz ohne reguläre Ausdrücke aus. Hier wird in der Methode identifyBulletPoints() in einer Schleife auf die verschiedenen Vorkommen von Aufzählungszeichen überprüft und diese dann durch Sternchen ersetzt. Warum eine neue myTrim()-Methode implementiert wurde, war mir nicht ganz klar. Die rekursive Methode prepareList() bringt dann die noch unstrukturierte Liste in die richtige Form.
private void identifyBulletPoints(ArrayList<<String>> tmp){
ArrayList<<String>> dummy= new ArrayList<<String>>();
for(int i=0; i<<tmp.size();i++){
dummy.add(myTrim(tmp.get(i)));
next = false;
for(int n=0;n<<pattern.length&!next;n++){
if(dummy.get(i).indexOf(pattern[n])==0){
if(pattern[n] == "o ")
final_version.add(dummy.get(i).replaceFirst(pattern[n], "* "));
else
final_version.add(dummy.get(i).replaceFirst(pattern[n], "*"));
next = true;
}
}
if(!next)
final_version.add(dummy.get(i));
}
}
private ArrayList<<String>> prepareList(ArrayList<<String>> a){
for(int i=0; i<<a.size();i++){
if(final_version.get(i).indexOf("*")!=0){
if(i>>>>0){
final_version.set(i-1, final_version.get(i-1).concat(" "+final_version.get(i)));
final_version.remove(i);
prepareList(final_version);
}
}
}
return final_version;
}
Aaron
- Sprache: Ruby
- LOC: 6
Zu guter Letzt, meine Version. Ich habe ebenfalls wie einige andere auch, die Aufzählungspunkte als Trenner für die split()-Funktion verwendet, anschließend die Leerzeichen entfernt und alle Zeilen die nicht mit einem Stern anfangen zur vorherigen hinzugefügt.
input = ""
while line = gets do input += line end
input.split(/^[\\s]*[-|\\*|#|>|+|o]|[\\d]+[.|:]?[\\s]*/).each do |line|
task = line.gsub(/ /, "").gsub(/\\n[\\s]*/, " ").strip
puts "* #{task}" unless task == ""
end
Analyse
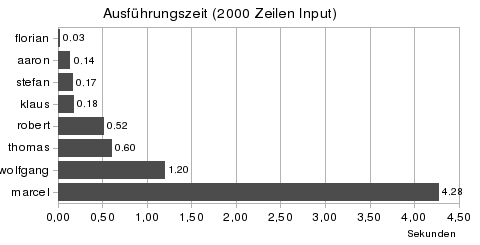
Ich habe mir überlegt, wie man diese Programme anständig miteinander vergleichen könnte. Da alle Programme das gleiche tun, habe ich mich für einen (zugegeben sehr primitiven) Benchmark entschlossen. Das Ergebnis war beeindruckend!
(Als Testumgebung musste mein AMD Duron 1.6 mit 1GB Ram und Ubuntu Linux 8.04 herhalten)
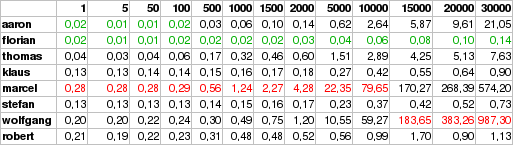
 (Die komplette Laufzeittabelle)
(Die komplette Laufzeittabelle)
{kind=link}
Florians Lösung (Ruby) scheint bereits auf Performance getrimmt zu sein, denn auch bei sehr großen Eingaben läuft das Programm innerhalb einer 10tel Sekunde durch. An der Programmiersprache kann es nicht liegen, da meine Ruby-Version ganze 21 Sekunden für 30 Tausend Zeilen braucht. Auch sehr schnell waren die PHP-Versionen von Stefan und Klaus. Hier glaube ich aber, dass die PCRE-Engine von PHP sehr viel an Zeit gespart hat, da gerade diese Funktionen die Kernpunkte der Sprache darstellen und dementsprechend optimiert wurden. Die Bash-Lösung von Thomas arbeitet sehr stabil, die Ausführungszeit steigt linear zum Input.
Erstaunt hat mich die Laufzeit der Java-Versionen von Robert und Wolfgang, hier gibt es sehr starke Unterschiede. Bei kleineren Inputs sind beide noch gleich auf, doch bei größeren Inputs bricht Wolfgangs Lösung sehr stark ein und braucht bei 30.000 Zeilen fast 17 Minuten. Grund dafür könnte die Bearbeitung auf Character-Ebene sein. Vielleicht weiß hier jemand eine treffendere Erklärung?
Die C#-Version von Marcel braucht auch bei kleineren Inputs schon recht lange. Einen Grund dafür könnte das zeichenweise Einlesen des Inputs sein, oder aber Mono ist schuld daran. (Ich habe die C#-Version mit dem Mono JIT-Compiler 1.2.6 übersetzt)
Wer den Benchmark selbst noch einmal auf seinem Rechner ausführen will, kann das gerne tun. Die komplette Testumgebung
einfach Entpacken und das Ruby-Skript starten.
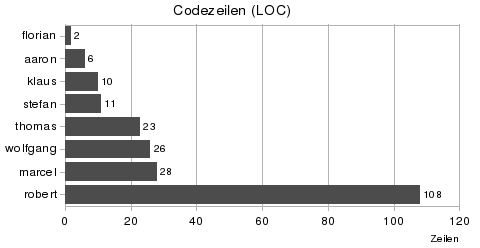
Auch interessant ist die Größe des Programmcodes. Florian hat es in zwei Zeilen geschafft, während Robert ganze 108 Zeilen benötigt hat. Über Übersichtlichkeit und Design lässt sich hier natürlich streiten, doch mir gefällt der Spruch Keep simple things simple
sehr gut :-) Natürlich liegt es hauptsächlich an der gewählten Programmiersprache und deren Features, wie viele Zeilen Code man braucht und welche Herangehensweise man wählt.
Bewertung
Hier seit ihr gefordert. Verwendet bitte die Kommentarfunktion am linken Seitenrand, um eure Meinung zum Code abzugeben.
Vielen Dank an alle fürs Mitmachen!
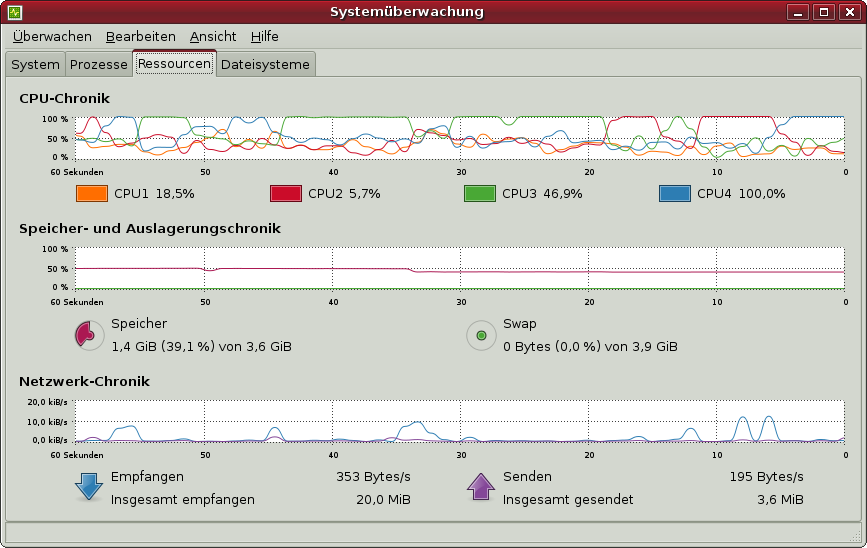
Nachtrag: Klaus und Florian haben sich die Mühe gemacht und den Benchmark bei sich auszuprobieren. Danke dafür! Erstaunlich ist, dass die Ergebnisse auf einem Windows-System etwas anders ausfallen, aber seht selbst:
Klaus
- CPU: AMD Phenom X4 9950 (4 x 2.6Ghz)
- RAM: 4GB DDR2 800Mhz
- OS: Ubuntu 64 Bit Hardy Heron
Testergebnisse, Systemauslastung
{kind=link}
Florian
- CPU: Intel Core 2 Quad CPU - 2.40GHz
- RAM: 2GB
- OS: WinXP SP3
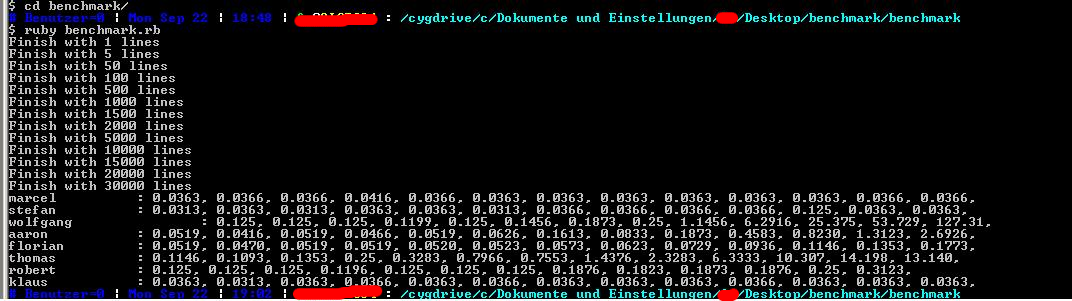{kind=link}